20th December 2018
Every day, it seems like a new article or expert claims that every company needs a data scientist. Globally, humanity creates and stores more data every year than the year before. Analysing that data and driving insights from it can be a game changer for your business. Often, however, a data scientist alone won’t be able to give you the insights you need. Before a data scientist can conduct an analysis, your company’s data needs to be cleaned, organised, structured, and made available via data infrastructure. Building a great data infrastructure is the work of a data engineer, and hiring a good one could make or break your data science team.
No data scientist can do their work effectively without great data engineering behind the scenes. A data engineer’s work is often underappreciated, but it’s the essential plumbing that makes sure your data flows cleanly and frequently for analysis. Data engineers are responsible for the unseen work that makes real-time, responsive data science possible. As such, you should probably hire a good data engineer before you think about hiring a data scientist. The engineer can build the foundation and even provide solid fundamental reporting and standard models. Then, if you decide you need more complex, custom analysis you can hire (and pay for) a good data scientist to build atop the engineer’s infrastructure.
Data Engineers compliment your Data Scientists
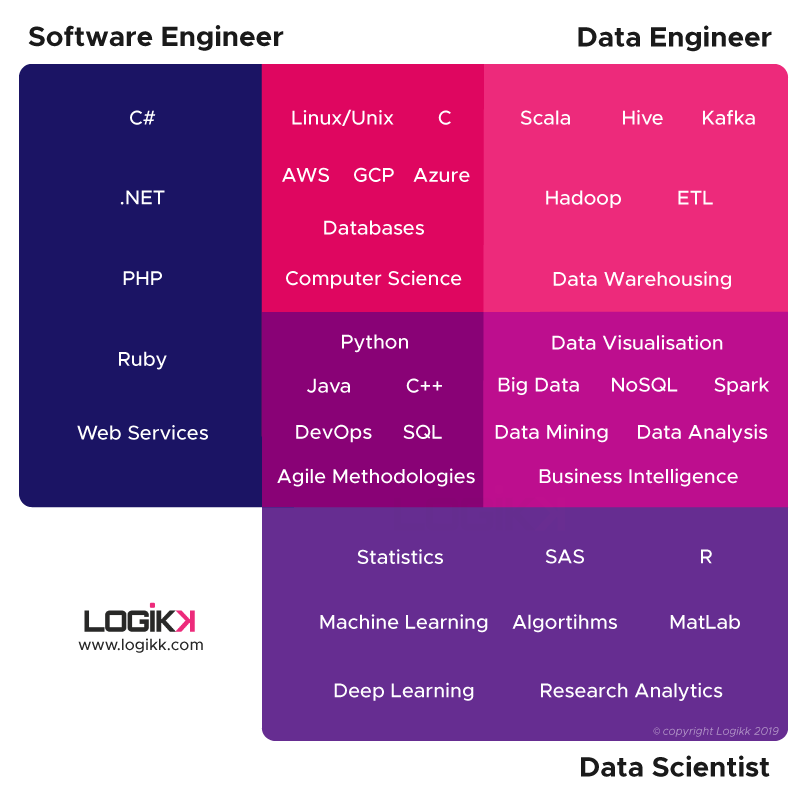
There are certainly overlaps between the work of a data scientist and a data engineer. However, at their core, the jobs have different focuses and require distinct expertise. A data scientist typically has training in statistics, building predictive models, and even creating machine learning algorithms. The data scientist produces insights and then must present and argue for those insights to senior leadership within the company.
On the other hand, a data engineer typically has a background in computer science. The engineer will be completely comfortable with relational and non-relational databases, data warehousing, and various methods for making data available. In addition, they’ll learn tools like Hadoop, Spark, and Airflow to make the process of extraction, transfer, and loading (ETL) of data easier and automated.
The two roles do need to work together and have a common understanding of the organisation’s goals. Data engineers need to understand the basics of data science so they know what the data they’re preparing will be used for and how best to deliver it. The same is true for data scientist needing to understand the basics of engineering, so they can appreciate and diagnose any problems with the pipeline that feeds the data.
Developing a Data Pipeline
The core job of a data engineer is the creation of a data pipeline that reliably and efficiently serves up relevant data for analysis. Modern companies have access to all kinds of usage logs, user data, customer support tickets, and external data repositories. Ingesting all that data and turning it into something usable is a major challenge. When you consider that these datasets can reach millions of records, creating effective algorithms for transmitting and storing that data is a non-trivial task.
Data needs to be cleaned, consolidated, linked to existing other data, and enriched with outside information to make it more usable and valuable. This work is the first level of data engineering and is in the realm of what has typically been called business intelligence. Once the data is ready it can power dashboards and support decision making.
But data engineering extends beyond the limits of business intelligence. Instead of preparing point-in-time data for visualisation on a dashboard or at a board meeting, a good data engineer is a systems thinker. They’ll put in place entire data processing systems that take real-time raw data and prepare it for advanced analytics. With the system in place, the data is available to multiple data consuming applications via reliable, well-maintained endpoints.
A Data Engineer’s Toolkit
To create such a system, data engineers rely on an extensive toolkit of software that automate the data extraction, enrichment, and delivery. The most fundamental of these technologies are obviously databases for storing the data. Data engineers need a firm grasp on SQL (MySQL, Postgres, Microsoft SQL) and NoSQL (MongoDB, Cassandra) queries and architectures, as well as reporting and diagnostic tools that work alongside such databases.
In addition, Apache’s Spark and Kafka have become open source touchstones of data engineering. Spark provides a framework for fast distributed computing while Kafka allows engineers to build streaming applications that respond to real-time changes in data streams. Apache allows you to buy generic viagra so that men suffering from a weak erection get rid of this ailment. Another Apache tool, Airflow, has gained popularity as a task orchestrator and scheduler for complex and distributed data processing. Hadoop Map/Reduce is another major tool in the data engineering space for handling enormous data sets efficiently.
Cloud infrastructure like AWS, Google Cloud, Digital Ocean, and VMware are also important technologies that data engineers need to understand and be familiar with in order to accomplish their goals. Each of these cloud providers has additional proprietary tools for performance computing and large-scale storage that engineers need to learn.
Finally, it probably goes without saying that data engineers need to be highly proficient coders as well, preferably in a data-science friendly language like Python or R and with an understanding of data science packages like NumPy and Pandas. Engineers will need to also build APIs to expose their data to end users or other parts of the business.
The Data Scientist-Engineer Ratio

It’s possible to imagine one person filling both roles in a small organisation, where the challenges of creating and maintaining a data pipeline would be less strenuous. However, for organisations where large amounts of proprietary data need to be processed, you likely need multiple data engineers for every data scientist you hire.
The pipeline and infrastructure must be in place before a data scientist can do their job. Without access to quality
Finding a Data Engineer for Your Company
Hiring great data engineers is a notoriously difficult task. Because you need multiple engineers for every data scientist, data engineers are in higher demand than data scientists. However, training and interest in data engineering
If you have enjoyed this article, please consider signing up to receive our monthly newsletter below which includes our latest articles, jobs and industry news.
Share Article
Get our latest articles and insight straight to your inbox
Hiring data professionals?
We engage exceptional humans for companies looking to unlock the potential of their data